Without implementing an actual load balancer between ClearPass and the NADs, about the easiest option is to configure multiple VIPs (one per cluster node) and set the backup such that hopefully the IP address stays active through any planned outages. That would also give you the opportunity to change the backup target from the ClearPass side rather than editing NAD configuration.
Original Message:
Sent: Oct 21, 2025 10:16 AM
From: fidgetyAP
Subject: AAA Dead Timers
Hi both,
We have four N3001 ClearPass appliances that are load balanced. Also, I've been told that the "sensible" function of checking that a server is back in service doesn't exist . RadSec is a workaround (as it uses TCP rather than UDP). We could increase the dead-time, but that's not necessarily the best solution, it would only postpone the issue rather than resolve it.
We're currently holding off on enabling RadSec due to CPU issues on our routers and want to avoid adding any additional load to them at this stage.
Original Message:
Sent: Oct 14, 2025 11:46 AM
From: vigan
Subject: AAA Dead Timers
Hey man,
According to the ArubaOS 8.6.0.0 User Guide (pp. 204–206), the controller marks a RADIUS server as down after consecutive retries and keeps it in that state for the configured dead-time (default 10 minutes). When the timer expires, the server is automatically reactivated without a reachability check, which can cause renewed authentication failures if the server remains offline.
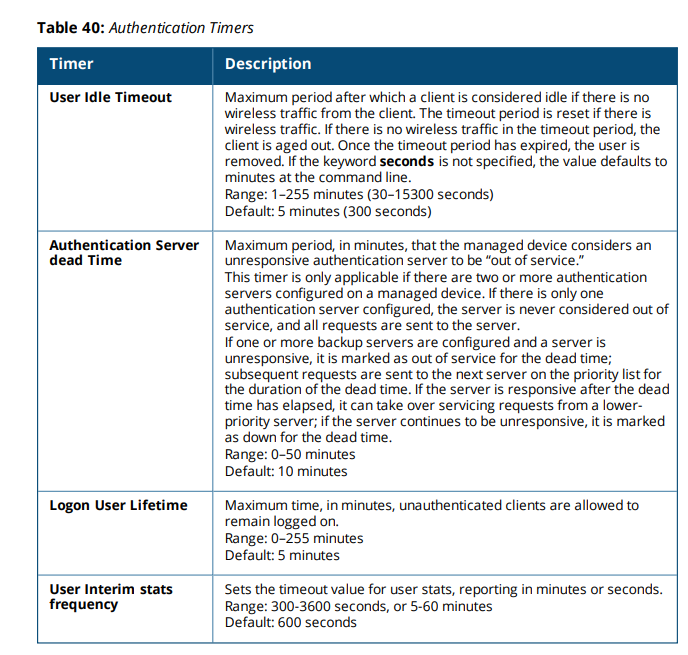
To mitigate this, increase the dead-time and enable load balancing within the AAA server group so traffic is distributed only among responsive ClearPass nodes.
I don't know if you have load-balancing enabled at this stage but if not here is how:
aaa server-group <group>load-balanceauth-server <cpass01>auth-server <cpass02>
At this stage I do not see anything on the official documentation that gives a straightforward fix to your exact issue.
Give this a try if you haven't already and see if it at least mitigates or resolves the issue.
Cheers,
Vigan
Original Message:
Sent: Oct 14, 2025 08:27 AM
From: fidgetyAP
Subject: AAA Dead Timers
Hi Vigan,
Thanks for your response. I'm a bit confused, as we're not seeing any false dead-server triggers, and we have four N3001 CPPM appliances to handle authentications and any proxying.
The issue we're encountering is a lack of redundancy. When a host goes down, authentication requests are still being sent to that (now dead) server. The problem arises after the dead-timer period lapses, the server is automatically marked as alive again without verifying its actual availability.
This leads to legitimate requests failing unnecessarily.
I'm waiting for TAC regarding AirGroup as there are log entries that suggest that this is affected too.
Best regards,
Anthony
Original Message:
Sent: Oct 14, 2025 07:30 AM
From: vigan
Subject: AAA Dead Timers
If you'd rather avoid RadSec, one workaround is to tune the RADIUS retry and timeout values on both the controller and ClearPass.
Set slightly higher retry_interval and deadtime on the controller, and reduce the response timeout on ClearPass so it replies faster under load.
Also, make sure your ClearPass cluster or server group is configured with multiple RADIUS hosts for redundancy - that helps smooth out transient UDP drops without false dead-server triggers.
The other solution is of course gateway of last resort, to be done with RADSec and using certificates signed with a Internal CA.
Cheers,
Vigan
Original Message:
Sent: Oct 14, 2025 06:55 AM
From: fidgetyAP
Subject: AAA Dead Timers
TAC has confirmed that the feature I'm looking for does not exist in AOS 8. They recommend submitting a feature request if we'd like it to be considered for future development.
"I am afraid to inform you that there is no keepalive mechanism available currently in 8.x architecture design.
We track the Radius Servers availability via authentication response from server. If there are multiple timeouts , the controller will mark it as dead."
They did suggest a workaround: enabling RadSec, which uses TCP instead of UDP, thereby requiring a reliable connection before authentication requests are sent. I've successfully tested this in our development environment.
I'm hesitant to enable it in our production environment due to the high volume of authentications our ClearPass servers handle. A separate TAC ticket confirmed that our 4 N3001 subscribers should be able to handle up to 1.8 million non-guest RADIUS using RadSec requests, which is reassuring.
Original Message:
Sent: Sep 30, 2025 09:37 AM
From: chulcher
Subject: AAA Dead Timers
The 'aaa test-server' feature is a command for manually validating an AAA server configuration, that is not a configuration item nor am I aware of a server tracking option.
------------------------------
Carson Hulcher, ACEX#110
Original Message:
Sent: Sep 30, 2025 05:33 AM
From: GorazdKikelj
Subject: AAA Dead Timers
I believe that corresponding feature in AOS8 is aaa test-server
https://arubanetworking.hpe.com/techdocs/CLI-Bank/Content/aos8/aaa-test-srv.htm
Best, Gorazd
------------------------------
Gorazd Kikelj
MVP Guru 2025
Original Message:
Sent: Sep 30, 2025 05:25 AM
From: fidgetyAP
Subject: AAA Dead Timers
I didn't because we running AOS 8. As far as I can, and I may be wrong, but wasn't the radius-server tracking command introduced in 10.07?
Original Message:
Sent: Sep 30, 2025 05:01 AM
From: GorazdKikelj
Subject: AAA Dead Timers
Did you try to implement radius tracking? It should provide exactly what you are looking for. It will test radius server availability and mark unresponsive ones. At least it solve the problem for me. Have no problems with dead radius servers as they stay marked as dead until reachable again by access tracker.
Best, Gorazd
------------------------------
Gorazd Kikelj
MVP Guru 2025
Original Message:
Sent: Sep 30, 2025 02:56 AM
From: fidgetyAP
Subject: AAA Dead Timers
Sorry for the delay, rather swamped at the moment.
Thank you! I was misunderstanding it.
I'm keeping my TAC case open though as it should ideally be tested with a spoof RADIUS request rather than a legitimate one!
Based on your response and @vigan's above, I have formulated another workaround in the mean time.
Thank you both!
Original Message:
Sent: Sep 22, 2025 03:04 PM
From: chulcher
Subject: AAA Dead Timers
The dead timer is how long the server will be marked as out of service once that has been determined. Once the timer has expired the controller will return that server back to the in-service list and the server will be tried again.
------------------------------
Carson Hulcher, ACEX#110
Original Message:
Sent: Sep 22, 2025 10:21 AM
From: fidgetyAP
Subject: AAA Dead Timers
Hi Vigan,
Thank you for your response.
Yes, once I identified the issue, I removed both servers from the server groups on both clusters.
The purpose of the dead timers is to avoid the need for manual intervention, especially if this were to happen outside of working hours.
Although we use the ClearPass VIPs for the captive portal and to access the active publisher, we don't use them for authentication due to the high volume of RADIUS requests they handle daily. At peak times, we have up to 50,000 clients connecting.
The configuration is designed to ensure resilience and reduce operational overhead during high-load or out-of-hours scenarios.